
Pour lire d’autres articles sur le développement logiciel, cliquez ici.
Quand on parle de logiciel, l’architecture est ce qui définit l’organisation, les dépendances, et l’interopérabilité entre les différents éléments composant un système.
Une bonne architecture logicielle permet de garder la solution stable et d’éviter la production de dette technique.
L’impact de l’architecture sur la qualité
La qualité d’un logiciel et son architecture sont deux choses fortement corrélées.
L’architecture étant la fondation sur laquelle on va développer le produit, les choix de conception préliminaires ne peuvent que fortement impacter sa qualité finale.
Le principe d’entropie logicielle
Quand un système est modifié, sa désorganisation, ou entropie, augmente systématiquement.
Ivar Jacobson
Selon le principe d’entropie logicielle, la dette technique d’un système ne fait qu’augmenter dans le temps, au fur et à mesure qu’il se complexifie.
Sans aucune contre-mesure, cette dette technique implique une augmentation des coûts de production et de maintenance liée à 3 facteurs :
- Perte de productivité des développeurs, à cause d’un code source de mauvaise qualité
- Perte de temps, à cause de corrections de bugs intempestives et nécessaires
- Perte de maintenabilité, le logiciel ne peut plus être modifié sans entraîner des effets de bord
Érosion de l’architecture logicielle

Dans le cas où l’équipe de développement ne prendrait pas en compte l’entropie logicielle, l’architecture du système s’érode jusqu’à pourrir (software rot).
Cette souillure du système a pour conséquence de rendre ce dernier impossible à maintenir à cause des effets de bord et de leurs coûts.
Le problème de l’érosion, c’est qu’elle se propage dans le code source de manière exponentielle.
Il s’agit de l’hypothèse de la vitre brisée : de la même manière qu’une simple vitre brisée peut encourager des délinquants à vandaliser tout un quartier, la simple présence de code de mauvaise qualité incitera le développeur à écrire à son tour du code de mauvaise qualité.
Au contraire, si le développeur rencontre du code source de bonne qualité, alors il aura tendance à essayer de le laisser dans un état au moins aussi bon que celui dans lequel il l’a trouvé.
Ainsi, procéder à du refactoring lorsque l’on trouve du code inutilement complexe, répétitif, ou mal découpé permet de réduire la dette technique tout au long du développement et donc de réduire considérablement le risque d’érosion.
Seulement, mettre en place ces bonnes pratiques ne suffit pas réduire de manière durable le taux de défaillance du logiciel.
Sans une bonne architecture, le système aura de plus en plus de mal à accueillir le changement sans introduire des effets indésirables.
La norme ISO 25010

Ayant pour objectif de standardiser les spécifications et l’évaluation de la qualité logicielle, la norme ISO 25010 définit 8 critères de qualité des produits logiciels :
- La capacité fonctionnelle
- La fiabilité
- L’efficacité
- La convivialité
- La sécurité
- La compatibilité
- La maintenabilité
- La portabilité
Voyons à quoi ils correspondent dans le détail :
Capacité fonctionnelle
Le produit doit répondre aux besoins des utilisateurs de manière :
- Complète : le produit possède toutes les fonctions dont il a besoin.
- Correcte : le produit délivre des résultats corrects avec le degré de précision approprié.
- Appropriée : les différentes fonctions accomplissent les tâches comme attendu.
Fiabilité
Le produit doit être :
- Mature : correspond aux attentes des utilisateurs en matière de fiabilité.
- Disponible : le produit est en service et accessible.
- Résilient : le système est capable d’opérer malgré la présence de fautes techniques
- Récupérable : le système est capable de récupérer ses données après une interruption de service.
Efficacité
Le produit doit être économe en :
- Temps
- Ressources
- Capacité
Convivialité
Le produit doit être facile à utiliser. On évalue cette facilité d’utilisation grâce aux critères suivants :
- Pertinence reconnaissable : il est facile de savoir si le produit peut répondre à un certain besoin ou non.
- Apprentissage : il est facile d’apprendre à utiliser le produit.
- Opérabilité : le produit est facile à utiliser.
- Protection contre les erreurs : le système est capable de protéger les utilisateurs de leurs propres erreurs.
- Esthétique : l’interface utilisateur est plaisante.
- Accessibilité : le produit peut être utilisé par le plus grand nombre.
Sécurité
Le système doit pouvoir empêcher des personnes non-autorisées ou mal-intentionnées d’accéder aux données.
La sécurité d’un système peut être évaluée selon ces 5 principes :
- Confidentialité : le système est capable d’assurer que les données ne sont accessibles qu’aux personnes autorisées.
- Intégrité : le système est capable d’empêcher l’altération des programmes et des données par des personnes non-autorisées.
- Non-répudiation : les actions et les événements sont enregistrées par le système.
- Responsabilité : les actions d’un utilisateur non-autorisé peuvent remonter jusqu’à lui.
- Authenticité : l’identité des ressources peut être prouvé
Compatibilité
La compatibilité d’un produit est définie par deux principes :
- Co-existence : le produit est capable d’opérer de façon efficace dans un environnement partagé avec d’autres produits.
- Interopérabilité : le système est capable d’échanger des informations avec des systèmes ou des produits tiers.
Maintenabilité
Pour être facilement maintenable, le système doit être :
- Modulaire : il est possible de modifier ou de remplacer un composant du système sans trop impacter les autres composants.
- Réutilisable : les composants du système peuvent être utilisés pour d’autres systèmes.
- Analysable : il est possible d’évaluer les impacts d’un changement dans le système de manière préliminaire et fiable et d’identifier facilement les causes des déficiences.
- Modifiable : le système peut être modifié sans dégrader la qualité.
- Testable : le système possède des procédures de tests pertinentes.
Portabilité
Pour pouvoir être « portable », et donc être transféré aisément d’un environnement à un autre, un logiciel doit être :
- Adaptable : le système est capable de s’adapter à l’évolution de son environnement.
- Installable : le système peut facilement être installé et désinstallé.
- Remplaçable : le produit peut remplacer un produit similaire de manière efficace et pertinente.
L’architecture monolithique
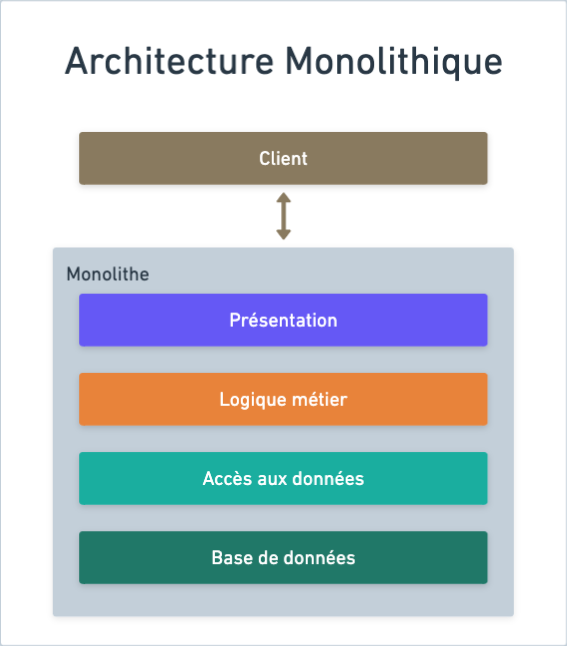
L’un des critères de qualité d’un logiciel est sa portabilité.
Pendant longtemps, le meilleur moyen de rendre un système portable était d’inclure absolument tous ses composants dans un unique exécutable, un monolithe.
Ne nécessitant aucune dépendance, le monolithe était ainsi prêt à l’emploi, et n’avait plus qu’à être lancé sur un serveur correctement configuré.
Un monolithe se compose généralement des couches suivantes :
- Base de données
- Accès aux données : le lien entre la base de données et le reste de l’application
- Logique métier : la logique programmatique liée aux fonctionnalités de l’application
- Présentation : la couche gérant les interactions entre l’utilisateur et le système
La problématique du scaling
La scalabilité, c’est la capacité d’un système à grandir ou à rapetisser en fonction de l’évolution de la demande.
On distingue 2 types de scaling :
- Le scaling vertical, qui consiste à augmenter physiquement les capacités du serveur pour qu’il puisse accepter une charge plus importante
- Le scaling horizontal, qui consiste à lancer d’autres instances du système sur d’autres serveurs afin de répartir la charge entre-eux
Contrairement à ce que certains pensent, il est tout à fait possible de scaler un monolithe, que ce soit verticalement ou horizontalement.
En revanche, les monolithes scalent mal.
Si le scaling vertical est en principe le plus simple à mettre en œuvre, il ne faut pas oublier qu’il y a toujours une limite physique à la puissance d’un ordinateur.
En d’autres termes, il y aura une charge limite au-delà de laquelle on ne pourra plus scaler.
Rien n’empêche non plus de scaler un monolithe de manière horizontale, mais ce qu’on gagne en fiabilité, on le perd en efficacité.
Le principe même du monolithe consiste à inclure l’entièreté du système dans un seul exécutable.
Seulement, la charge de travail n’est jamais répartie uniformément à travers un système.
Si je veux scaler ma base de données, je suis donc obligé de lancer toute une instance de mon monolithe, incluant des couches qui n’ont pas besoin d’être scalées, comme la couche de présentation par exemple.
Les infrastructures en micro-services
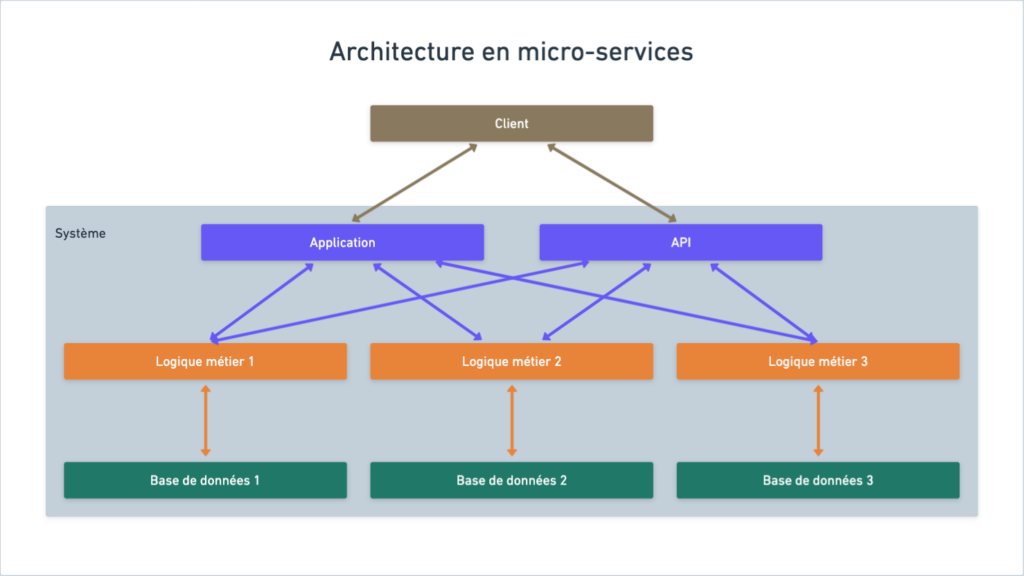
Avec l’apparition d’outils de virtualisation et d’orchestration tels que Docker et Kubernetes, il est devenu bien plus facile de rendre ses applications portables et scalables, donc fiables.
En conséquence, les infrastructures en micro-services ont fini par envahir l’industrie, balayant au passage l’architecture monolithique.
Ce type d’infrastructure consiste à diviser le système en plusieurs applications modulaires faiblement dépendantes les unes des autres.
Cette approche permet non-seulement d’améliorer la fiabilité du logiciel, mais elle améliore également sa maintenabilité, puisqu’elle rend les effets de bords limités par nature.
Clean Architecture
La Clean Architecture est une architecture adaptée aux micro-services dont l’objectif principal est de réduire les relations de dépendances avec les services extérieurs, et de limiter le couplage, c’est-à-dire les relations de dépendance entre les composants eux-mêmes.
Selon la Clean Architecture, la logique métier doit être :
- Testable
- Indépendante des frameworks
- Indépendante des interfaces utilisateur
- Indépendante des bases de données
- Indépendante des services externes
Pour faire simple, il faut pouvoir remplacer tous les éléments qui ne concernent pas directement votre Domaine (entités + logique métier) simplement.
Cela inclut vos applications frontend, vos systèmes de gestion de bases de données, les modules que vous utilisez, et les fournisseurs tiers sur lesquels vous vous appuyez.
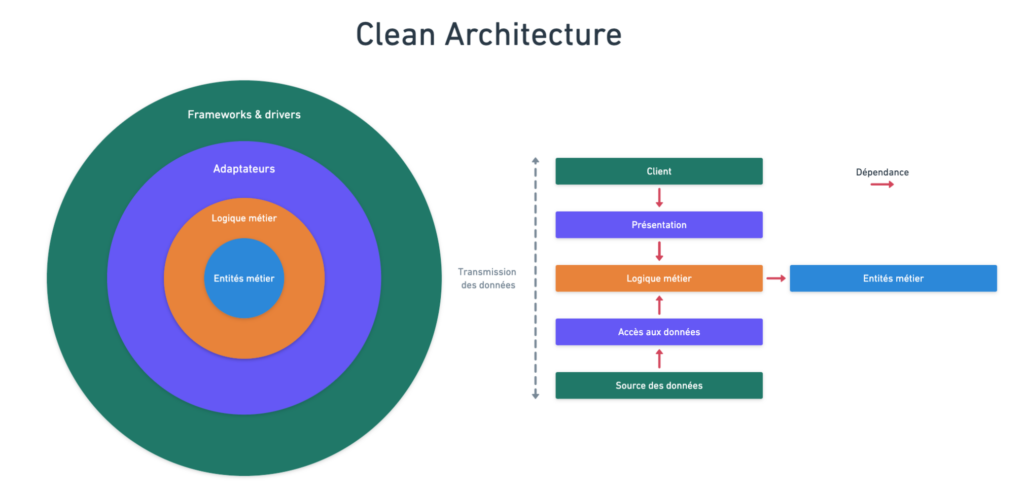
Organisation de la Clean Architecture
La Clean Architecture organise ses différentes couches telle une cible où les couches les plus remplaçables enveloppent les couches les plus essentielles.
Ces couches sont, en partant de l’intérieur :
- Entités métier : la modélisation programmatique des choses que vous allez manipuler.
- Logique métier : l’ensemble du code permettant de réaliser les cas d’utilisation.
- Adaptateurs : l’ensemble des passerelles entre votre logique métier et l’extérieur, que ce soit des services tiers, comme des utilisateurs.
Concrètement : des applications web, des applications mobiles, des APIs et des processus automatisés, des bibliothèques d’adaptateurs, des bibliothèques de Data Access Objects - Frameworks & drivers : l’ensemble de ce qui existe en-dehors du système.
Concrètement : des bases de données, des APIs tierces
Les dépendances ne pouvant aller que de l’extérieur vers l’intérieur, un adaptateur dépendra de la logique métier, mais la logique métier ne pourra en aucun cas dépendre d‘un adaptateur.
À noter cependant que la Clean Architecture ne parle que de dépendances d’implémentation.
Le fait que les bases de données se situent techniquement dans la couche extérieur ne rend pas pour autant la couche d’infrastructure dépendante de cette dernière, du moment qu’une couche d’abstraction existe bien entre les deux.
De plus, un composant dans la Clean Architecture ne se traduit pas forcément en micro-service.
Ici, un micro-service sera une interface dépendant de bibliothèques communes à d’autres micro-services, telles que les entités et les adaptateurs.
Les tests dans la Clean Architecture
Le code étant séparé en couches distinctes et relativement peu dépendantes les unes des autres, il devient plus facile de le tester correctement.
Ainsi, les tests peuvent être effectués par couche, en mockant les éventuelles dépendances.
Vertical Slice Architecture
Tout comme la Clean Architecture, la Vertical Slice Architecture est une architecture adaptée aux micro-services qui vise à réduire les relations de dépendance entre le système et l’extérieur, et au sein du système lui-même.
La différence réside dans leurs approches respectives.
La Vertical Slice Architecture s’appuie sur deux dogmes :
- Les choses qui changent ensemble vont ensemble.
- Il faut maximiser la cohésion (les choses liées vont ensemble) et minimiser le couplage (les relations de co-dépendance entre les composants).
… et trois principes :
- Le système doit être centré autour des fonctionnalités.
- Il ne doit pas y avoir de barrières entre les couches du système.
- Le changement ne doit s’opérer que sur un seul endroit à la fois.
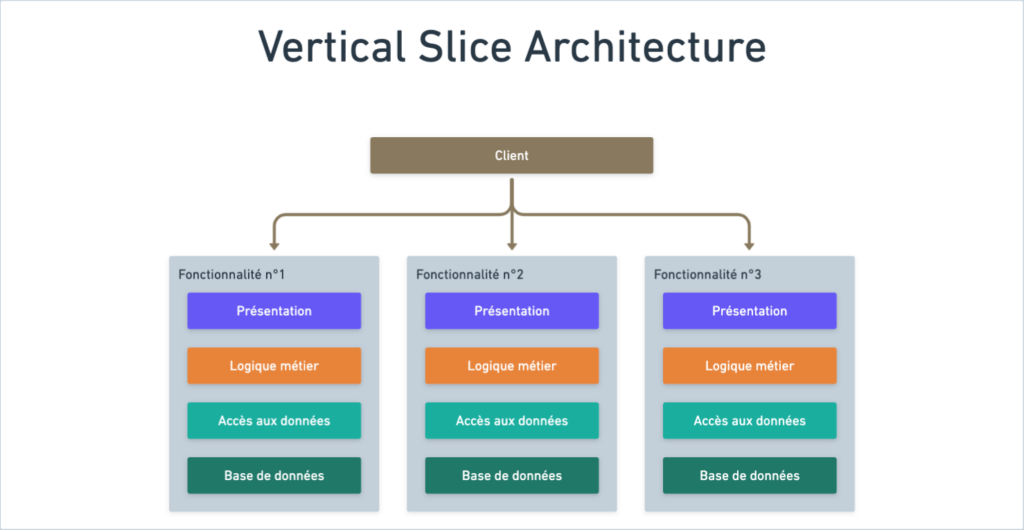
Là où la Clean Architecture découpe le système en couches techniques, la Vertical Slice Architecture le découpe en fonctionnalités.
Chaque tranche vertical du système possède sa propre couche de présentation et sa logique métier, toutes deux établies sur un domaine, et une base de données pouvant être commune à d’autres tranches verticales.
Pour simplifier, on pourrait dire qu’une tranche verticale est une sorte de mini-monolithe s’occupant exclusivement d’une fonctionnalité.
Au lieu de scaler les différentes couches techniques, on fera scaler les fonctionnalités elles-mêmes.
L’avantage de la Vertical Slice sur la Clean Architecture, c’est qu’elle produit en fin de compte moins de couplage, tout en réduisant le niveau d’abstractions à créer pour maintenir une architecture qualitative.
Cela ne veut pas nécessairement dire qu’elle est meilleure, mais elle offre une approche différente.
Monolithe, Clean, ou Vertical Slice ?
Réponse courte : ça dépend !

Même si on utilise de moins en moins l’architecture monolithique de nos jours, elle reste tout de même la plus simple et la moins coûteuse à mettre en place pour les petits projets.
Dans le cas où vous devriez vous diriger vers des micro-services, le choix entre la Clean Architecture et la Vertical Slice dépend presque entièrement de la façon dont vous préférez approcher le développement.
Certes la Vertical Slice Architecture vous fera gagner du temps en vous épargnant quelques couches d’abstractions, mais peut-être qu’un découpage en couches techniques semblera plus cohérent pour vous.
De plus, moins d’abstraction signifie aussi plus de dépendances, ce qui pourrait nuire à la maintenabilité de votre système.
Concevoir c’est choisir, et il y a rarement d’option fonctionnant dans toutes les situations.
Le mieux reste encore de visualiser votre système dans son entièreté, et de choisir ce qui semble être le plus adapté à sa situation.
Pour aller plus loin
Architecture logicielle : https://fr.wikipedia.org/wiki/Architecture_logicielle
Erosion de l’architecture logicielle : https://fr.wikipedia.org/wiki/%C3%89rosion_de_l%27architecture_logicielle
L’entropie logicielle, pourquoi la dette technique ne fait qu’augmenter ? https://lilobase.wordpress.com/2014/05/27/lentropie-logicielle-pourquoi-la-dette-technique-ne-fait-quaugmenter/
What is ISO 25010 : https://www.perforce.com/blog/qac/what-is-iso-25010
monolithic architecture : https://www.techtarget.com/whatis/definition/monolithic-architecture
Qu’est-ce que la Clean Architecture ? https://www.adimeo.com/blog/forum-php-2019-clean-architecture
Clean Architecture Guide : https://proandroiddev.com/clean-architecture-data-flow-dependency-rule-615ffdd79e29
Restructuring to a Vertical Slice Architecture : https://codeopinion.com/restructuring-to-a-vertical-slice-architecture/
How to Implement Vertical Slice Architecture : https://garywoodfine.com/implementing-vertical-slice-architecture/