Le World Wide Web est le système documentaire d’Internet. À l’instar de l’email qui permet d’envoyer des messages à d’autres utilisateurs, le Web permet de consulter des documents de différentes natures reliés les uns aux autres comme dans une espèce de gigantesque toile d’araignée.
Cette notion de documents de différentes natures reliés les uns aux autres, c’est ce qu’on appelle l’hypermédia. Il s’agit du principe autour duquel le Web est construit, et pourtant cette notion tombe dans l’oubli.
Prenons en exemple un projet hypermédia que l’on connaît tous : Wikipédia.
Chaque article de Wikipédia est une ressource hypertexte reliée à d’autres articles Wikipédia (hyperliens internes), et reliée à des sources documentaires sur le Web (hyperliens externes profonds).
De plus, un article Wikipédia peut être relié à d’autres ressources de la Wikimédia Foundation, tels que des médias hébergées sur Wikimedia Commons, ou des fiches de la base de connaissances Wikidata.

Mais aujourd’hui, nous ne faisons plus les choses comme ça.
On ne développe plus des sites web reliés les uns aux autres, mais des applications qui fonctionnent en silos, et qui tentent de vous retenir à l’intérieur par des avertissements balourds.
Attention, il ne faudrait pas que vous accordiez votre attention à quelqu’un d’autre que nous.
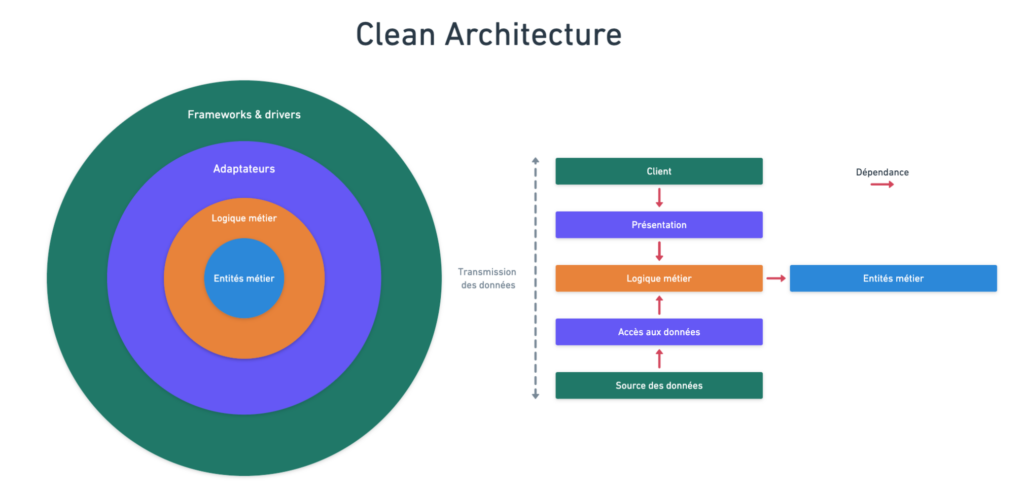
Et dans le même temps, quelques hurluberlus ont passé les années 2010 à évangéliser certaines pratiques de développement, sans prendre le temps de les comprendre, ni même de s’apercevoir que non : il n’y a pas de baguettes magiques.
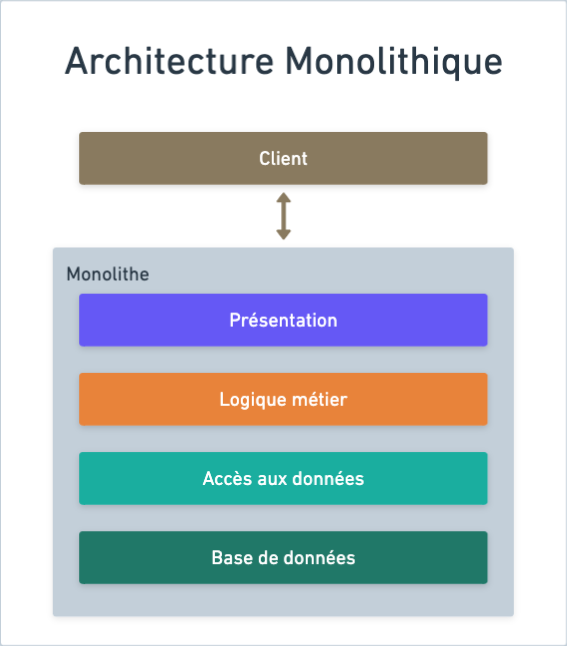
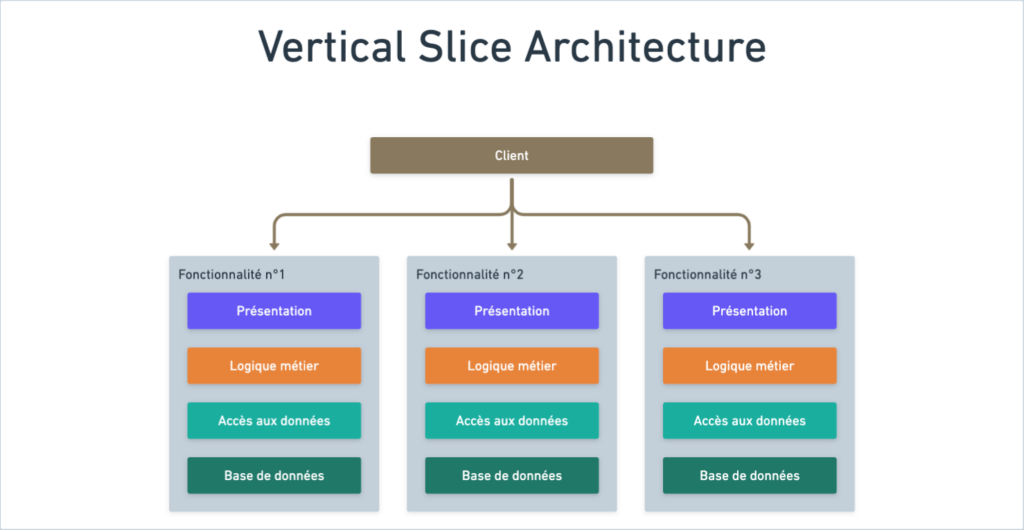
Quoi, tu fais encore du SQL ? Du MVC ? Des monolithes ? Des requêtes AJAX ? Tu es bloqué dans les années 2000 ou quoi ?
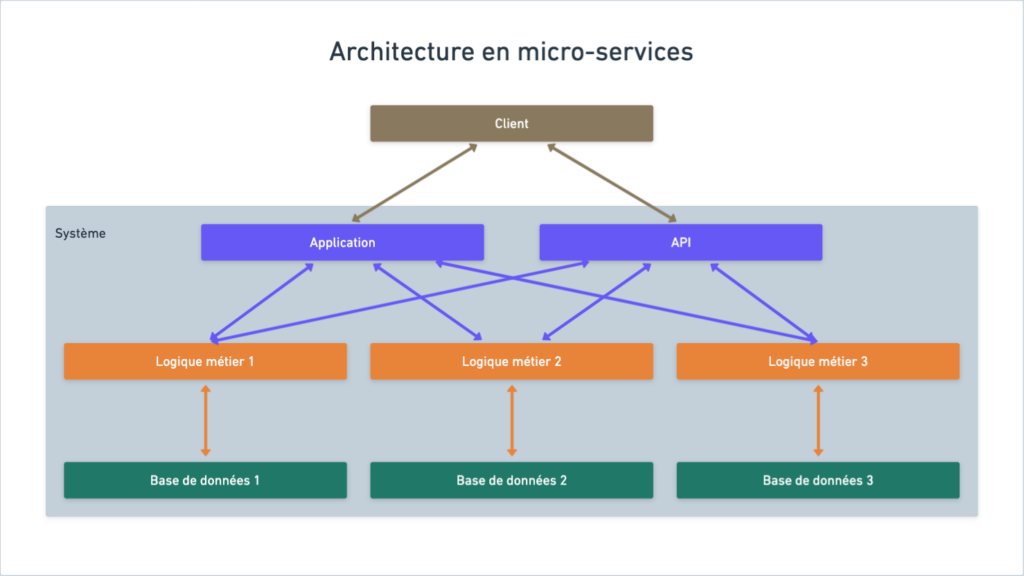
Maintenant, il faut faire du Scrum ! Utiliser des frameworks front-ends ! Faire des micro-services ! Utiliser des bases de données noSQL ! Faire du REST !
Je n’aime pas Scrum et j’aime de moins en moins les frameworks frontend, par contre j’aime assez REST… mais est-ce que quelqu’un parmi eux sait au moins ce que c’est ?
C’est quand le serveur expose des actions CRUD et répond en JSON !
« Ah ! Non ! C’est un peu court, jeune homme ! »
Pourtant il y a des choses à dire, parce que comprendre REST c’est comprendre le Web.
Alors, qu’est-ce que REST, réellement ?
REST signifie Representational State Transfer.
REST, ce n’est pas un format de sortie, c’est un style d’architecture — celle pensée pour le Web — qui doit respecter les six contraintes suivantes, définies par Roy Fielding dans sa thèse Architectural Styles and the Design of Network-based Software Architectures :
- Les responsabilités sont découplées entre le client et le serveur (celle là est simple, en principe tout le monde la respecte)
- La communication entre le client et le serveur s’effectue sans état, c’est-à-dire que le client a la responsabilité de fournir toutes les informations nécessaires pour que le serveur puisse répondre (ici aussi, généralement peu de problèmes)
- Le serveur doit fournir les informations nécessaires pour que le client puisse déterminer quelles information mettre en cache sans risquer de stocker des données obsolètes. (si votre application frontend décide d’elle-même ce qu’elle met en cache ou non, vous sortez ici)
- Le client ne doit pas être capable de savoir s’il est connecté au serveur final ou à un serveur intermédiaire (si vous avez une URL d’API différente pour chaque région, vous n’êtes pas REST)
- Le serveur a la possibilité d’ajouter des fonctionnalités au client en lui injectant des scripts (attendez, on peut faire ça avec du JSON ?)
- Le plus important : le serveur doit présenter une interface uniforme. (et ça, on le trouve très rarement)
Pour avoir une interface uniforme, le serveur doit :
- Fournir au client des représentations de ressources qu’il peut manipuler à l’aide d’actions métiers (et non pas un bête CRUD)
- Permettre des requêtes auto-descriptives utilisant les verbes HTTP et des URIs sémantiques pour identifier des ressources spécifiques (cependant REST ne dit pas comment une ressource doit être identifiée)
- Fournir des réponses auto-descriptives qui permettent de naviguer vers d’autres ressources et d’autres actions à l’aide d’hyperliens
Quand on applique REST, l’hypermédia devient le moteur d’état de l’application, c’est-à-dire que le rôle du serveur n’est pas juste de nous renvoyer une représentation de la donnée, mais également de nous indiquer comment on peut interagir avec et à quoi elle est liée.
L’hypermédia comme moteur d’état de l’application
REST n’impose pas de format de réponse : tout est permis. Mais avouons-le : c’est quand même assez étrange de représenter des hyperliens en JSON…
Alors peut-être qu’il est temps de se souvenir du hypertext dans le terme Hypertext Transfer Protocol.
REST n’impose pas de format de réponse, mais il est pensé pour le Web, et le Web est fait d’hypertexte.
Tu n’y penses pas ?! C’est vraiment très important d’avoir une API qui répond en JSON et une application JavaScript qui fait des requêtes au serveur pour construire l’interface à partir du JSON !
Vraiment ? Et qu’est-ce qu’on y gagne, en fait ?
En tant que développeurs Web, nous travaillons sur la partie la plus relativement simple et facile du spectre du génie logiciel. Et pourtant on a passé les dernières années à se compliquer la vie avec des concepts sortis de nul part, alors que nous n’avions qu’à suivre les recommandations des fondateurs dudit Web.
C’est à croire que le développeur Web s’invente des problèmes car il n’en a pas assez.
Il va sans dire que les développeurs de kernels n’ont pas les mêmes débats.
Comment mettre en place une architecture REST aujourd’hui ?
Pour appliquer REST, vous avez principalement besoin d’une seule chose : un serveur web qui répond du HTML par défaut.
Et en faisant cela, vous simplifiez déjà grandement l’architecture logicielle de votre solution. Il n’y a qu’un seul point d’entrée : le serveur.
Vous n’avez pas besoin d’avoir une application React/Svelte/Vue en plus. Le navigateur internet suffit pour utiliser l’API.
Et si vraiment vous tenez à avoir une application JavaScript, elle n’a pas besoin d’intégrer de la logique métier en plus. Seulement d’afficher ce que le serveur lui dit d’afficher.
Quels outils ?
L’avantage du vrai REST, c’est que vous n’avez pas besoin de toucher à JavaScript si vous ne le voulez pas.
Vous pouvez utiliser n’importe quel langage et n’importe quelle technologie, à condition que vous puissiez faire un serveur web avec.
Côté frontend, je vous suggère d’intégrer les librairies HTMX et AlpineJS, qui permettent respectivement d’ajouter du contenu dynamique et de la gestion d’états sans avoir à écrire une seule ligne de JavaScript.
Toutefois, si vous aimez TypeScript, je vous conseille Astro : un framework permettant de créer des sites statiques et de faire du rendu côté serveur. Contrairement à une application React qui est exécutée sur le navigateur, Astro renvoie du HTML prêt à l’emploi au navigateur.
De plus, Astro permet aussi d’intégrer des composants de frameworks frontend, tels que React, Vue, et Svelte, si pour une raison ou pour une autre cela s’avérait nécessaire pour votre projet.
« Mais j’ai besoin que des clients tiers puissent utiliser mon API ! »
Ce n’est pas un problème.
Deux choix s’offrent à vous :
- Si le client tiers est capable d’interpréter du HTML, il peut directement afficher la réponse du serveur
- Sinon, renvoyez une représentation de la donnée dans un format plus adapté
Dans un système REST, la réponse par défaut devrait être de l’hypertexte, mais rien n’empêche d’ajouter d’autres formats comme le JSON, XML, CSV.
C’est ce que fait l’API MediaWiki qui permet d’interroger Wikipédia : dans l’URL vous pouvez spécifier un paramètre `format=json` qui changera le format de la réponse.
Vous pouvez également accomplir quelque chose de similaire avec un `.json` en fin d’URL, ce qui à titre personnel me paraît un peu plus joli.
Ma règle générale serait de créer d’abord la version HTML de la page, puis éventuellement une version JSON qui sera toujours basée sur la version hypertexte.
Par exemple, si la version HTML de votre page présente un hyperlien, la version JSON pourrait contenir la paire clé-valeur suivante :
{
"link": {
"label": "Mon lien",
"method": "GET",
"href": "/foo.json"
}
}
Malheureusement, il n’existe pas de standard clairement établi pour représenter l’hypermédia en JSON, mais l’important ici est de faire en sorte de fournir un document le plus auto-descriptif possible.
Le client doit être capable d’interpréter la réponse du serveur sans connaissance préalable – autre que la façon dont l’hypermédia est représenté – et sans intégrer de la logique métier.
Exemple d’une ressource représentée sous différents formats
Soit la réponse hypertexte de la ressource `/users/john-doe` :
On pourrait imaginer une version JSON de cette même ressource à une adresse `/users/john-doe.json` comme suit :
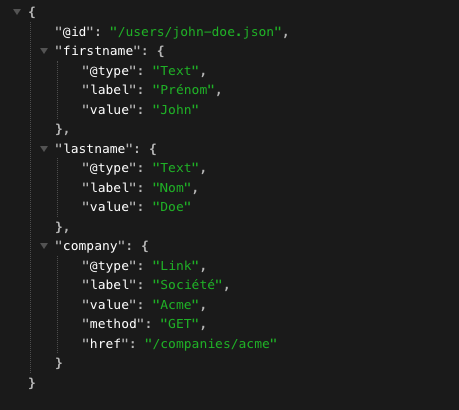
Certes la réponse est un peu plus verbeuse que dans une API JSON plus « classique », mais le client qui recevra cette réponse saura que la ressource utilisateur « John Doe » est liée à la ressource société « Acme » qui peut être consultée à l’adresse `/companies/acme`.
Et si le client accédant à la page de John Doe n’est pas autorisé à consulter la page d’Acme, on pourra toujours remplacer l’objet `Link` par un objet `Text` pour le lui faire comprendre.
Exemple n° 2 : représenter des actions pouvant être effectuées sur une ressource
Soit la réponse hypertexte du serveur pour la ressource société « Acme » :

Contrairement à l’exemple précédent, ici nous avons des textes, un lien vers une autre ressource, mais également des actions qui peuvent être effectuées sur Acme : Modifier, Gérer les employés, et Supprimer la société.
Nous pourrions essayer de représenter cette réponse en JSON de la manière suivante :
En résumé
Les grands principes de REST
- La logique métier se trouve exclusivement sur le serveur.
- Le serveur doit donner des réponses auto-descriptives que le client peut interpréter sans connaissance préalable.
- Les différentes ressources et actions proposées par le serveur sont reliées entre-elles — et reliées au reste du Web — au sein d’une toile de liens et de redirections. (L’hypermédia est le moteur d’état de l’application)
Les avantages de REST
- Une architecture simplifiée : votre frontend et votre backend sont gérés au même endroit. Un seul point d’entrée, une seule application à maintenir.
- Pas de désynchronisations frontend–backend : si le serveur a la main-mise sur la logique métier, le frontend ne peut plus faire des suppositions erronées sur les entrées-sorties du serveur
- Une vraie séparation des responsabilités : certaines actions comme le client-side-routing ne sont plus gérés en JavaScript, mais par le navigateur qui est là pour ça.
- Un versionnage simplifié : une API REST n’est pas versionnée à proprement parler, elle évolue. Le serveur renvoie une représentation hypermédia de la donnée et non la donnée en tant que tel, cela signifie que cette représentation peut évoluer pour intégrer de nouvelles composantes, et que les formats de données en interne peuvent changer sans impacter la représentation.
- Une architecture plus sécurisée : en prenant le temps de travailler les représentations de vos ressources pour n’inclure que le strict nécessaire, vous réduisez le risque d’exposer de la logique interne qui pourrait être exploitée par des acteurs malveillants.
- Des meilleures performances par rapport à une application JavaScript qui serait exécutée par le navigateur.
- Une API auto-documentée : les réponses étant compréhensibles sans connaissance préalable, un tiers peut utiliser votre API sans avoir à en comprendre tous les tenants et aboutissants, même si une documentation minimale restera nécessaire pour expliquer les modalités d’accès.
- Un Web plus cohérent : vous développez un maillon dans un système documentaire international basé sur une philosophie spécifique, et vous respectez cette philosophie. C’est cette philosophie qui nous permettra à l’avenir de bâtir des communs numériques où chaque acteur pourra mettre son expertise à la disposition des autres au sein d’un grand système documentaire commun.
That’s all Folks!
Si cet article vous a donné envie d’appliquer REST correctement, je ne peux que vous conseiller de commencer à expérimenter et à approfondir vos connaissances du sujet (les liens en bas sont un bon point de départ).
Ne foncez pas tête baissée non plus. Malgré tout ce qui a été dit ici, une API RPC peut être pertinente. Cela dépend de votre projet. Il s’agit avant tout de rester pragmatique.
Souvenez-vous d’une chose : il n’existe pas de baguette magique.
« M’ouais, mais je suis toujours pas convaincu »
Cela demande un certain temps de se désintoxiquer des fameuses « bonnes pratiques » que l’industrie a érigé en baguettes magiques ces dix dernières années.
Cela m’a pris aussi quelques mois, mais à force de chercher et d’expérimenter, j’ai fini par comprendre.
Peut-être que cet article n’aura pas achevé de vous convaincre, mais au minimum il aura permis de planter une graine dans votre esprit.
Peut-être que dorénavant vous allez vous mettre à grincer des dents quand quelqu’un dira que votre serveur web qui retourne du JSON est une « API REST ».
Peut-être qu’un jour vous aurez un problème avec votre serveur et votre application React, et vous vous direz que tout ceci pourrait être plus simple.
Peut-être même que vous vous direz que ça ne peut pas être comme ça que le Web a été imaginé à la base.
Pour aller plus loin
Hypermédia (article) : https://fr.wikipedia.org/wiki/Hyperm%C3%A9dia
Hyperlien (article) : https://fr.wikipedia.org/wiki/Hyperlien
Representational state transfer (article) : https://fr.wikipedia.org/wiki/Representational_state_transfer
HATEOAS (essai) : https://htmx.org/essays/hateoas/
How Did REST Come To Mean The Opposite of REST? (essai) : https://htmx.org/essays/how-did-rest-come-to-mean-the-opposite-of-rest/
A Response To « Have Single-Page Apps Ruined the Web? » (essai) : https://htmx.org/essays/a-response-to-rich-harris/
Hypermedia Systems (livre) : https://hypermedia.systems/